Local RAG 솔루션
kvidAI Local RAG 솔루션은 기업의 내부 문서를 안전하게 활용할 수 있는 온프레미스 RAG(Retrieval-Augmented Generation) 시스템입니다. 모든 데이터가 기업 내부에서만 처리되어 보안과 프라이버시를 보장합니다.
🎯 주요 기능
AI 에이전트
에이전트는 기본적으로 간단한 도구에 액세스할 수 있는 LLM입니다. 모든 에이전트는 작업 공간에서 동일한 도구를 공유하지만, 호출된 작업 공간 내에서 작동합니다.
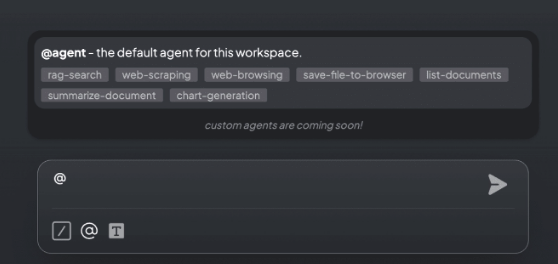
작업 공간으로 이동하여 @agent <your prompt>를 입력하면 에이전트 세션을 시작할 수 있으며, exit를 입력하기만 하면 종료할 수 있습니다.
에이전트 기능:
- 웹 스크래핑: 웹사이트에서 정보 수집
- 문서 관리: 문서 나열, 요약, 검색
- 웹 검색: 인터넷 검색 수행
- 차트 생성: 데이터 시각화 및 차트 작성
- 파일 저장: 데스크톱과 자신의 메모리에 파일 저장
API 액세스 및 키 관리
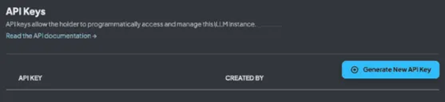
- API 문서: 인스턴스에서 사용 가능한 엔드포인트에 대한 API 설명서를
/api/docs에서 확인 가능 - API 키 관리: 올바른 액세스 수준을 갖춘 계정에서 API 키 관리
- 개발자 API: 작업 공간을 관리, 업데이트, 포함하고, 심지어 채팅하는 데 사용할 수 있는 전체 개발자 API 지원
- 즉시 생성/삭제: 권한이 부여된 경우 API 키를 즉시 생성하고 삭제 가능
API 키가 있는 사람은 누구나 Local RAG를 사용할 수 있으므로 이 키를 어디에도 공유하거나 공개하지 마세요.
외관 커스터마이징
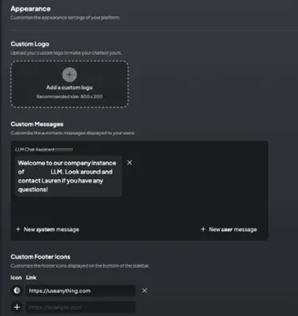
Local RAG는 사용자가 원하는 브랜딩에 맞게 인스턴스의 모양과 느낌을 커스터마이징할 수 있습니다.
📊 데이터 관리
채팅 로그 내보내기
Local RAG는 다음 형식으로 채팅 로그 내보내기를 지원합니다:
- CSV: 스프레드시트 호환 형식
- JSON: 구조화된 데이터 형식
- JSON(Alpaca): Alpaca 모델 호환 형식
- JSONL(OpenAI fine-tune): OpenAI 파인튜닝용 형식
최소 10개의 채팅 로그가 사용 가능해지면 화면 상단에서 내보내기를 클릭하기만 하면 됩니다. 올바른 계정 권한이 있다면 RAG 인스턴스의 작업 공간 및 사용자별 채팅 로그를 볼 수 있습니다.
임베딩 채팅 위젯
RAG 솔루션을 사용하면 간단한 <script> 태그를 사용하여 모든 웹사이트에 쉽게 통합할 수 있는 내장형 채팅 위젯을 만들 수 있습니다.
구성 옵션
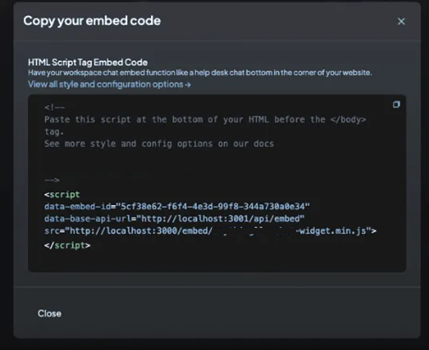
작업 공간 설정
- 채팅 창이 어떤 작업 공간을 기반으로 할지 결정
- 특정 구성 옵션에 의해 재정의되지 않는 한 모든 기본값은 선택한 작업 공간에서 상속
채팅 방법
- 채팅: 챗봇은 맥락에 관계없이 모든 질문에 답변
- 질의: 챗봇은 작업 공간의 문서와 관련된 채팅에만 응답
보안 및 제한 설정
- 도메인 요청 제한: 지정된 목록이 아닌 다른 도메인에서 오는 모든 요청 차단
- 하루 최대 채팅: 24시간 동안 처리할 수 있는 채팅 수 제한
- 세션당 최대 채팅: 세션 사용자가 24시간 동안 보낼 수 있는 채팅 수 제한
동적 설정
- 동적 모델 사용: 선호하는 LLM 모델 설정이 작업 공간 기본값을 재정의
- 동적 LLM 온도: LLM 온도 설정이 작업 공간 기본값을 재정의
- 프롬프트 재정의: 시스템 프롬프트 설정이 작업 공간 기본값을 재정의
이벤트 로그 모니터링
RAG의 이벤트 로그 페이지를 통해 사용자는 애플리케이션 내에서 발생하는 다양한 이벤트를 보고 모니터링할 수 있습니다.
추적 이벤트:
- 사용자 로그인 시도 (성공 및 실패)
- 사용자가 보낸 메시지
- 애플리케이션 설정에 대한 변경 사항
- 문서 업로드
각 이벤트에는 이벤트 유형, 관련 사용자(해당되는 경우), 타임스탬프, 이벤트 유형에 대한 추가 세부 정보 등의 관련 정보가 포함되어 있습니다.
🔧 기술 구성
임베딩 모델 지원
Local RAG는 거의 설정 없이도 바로 사용할 수 있는 많은 임베딩 모델 공급자를 지원합니다. 임베딩 모델은 텍스트를 벡터로 변환하는 특정 유형의 모델로, 벡터 데이터베이스에 저장하고 검색할 수 있습니다.
로컬 임베딩 모델:
- Built-in (기본값)
- Ollama
- LM Studio
- Local AI
클라우드 임베딩 모델:
- OpenAI
- Azure OpenAI
- Cohere
언어 모델 지원
Local RAG를 사용하면 채팅과 생성 AI를 위한 다양한 LLM 공급자를 사용할 수 있습니다.
로컬 언어 모델:
- Built-in (기본값)
- Ollama
- LM Studio
- Local AI
클라우드 언어 모델:
- OpenAI
- Azure OpenAI
- AWS Bedrock
- Anthropic
- Cohere
- Google Gemini Pro
- Hugging Face
- Together AI
- OpenRouter
- Perplexity AI
- Mistral API
- Groq
- KobaldCPP
- OpenAI(generic)
음성 전사 모델
Local RAG에서는 사용자 정의 오디오 전사 서비스 제공자를 지원합니다.
로컬 전사 모델:
- Built-in (Xenova)
클라우드 전사 모델:
- OpenAI
벡터 데이터베이스
Local RAG 솔루션에서는 LanceDB가 구동하는 개인 내장 벡터 데이터베이스가 함께 제공됩니다. 기본 옵션을 사용하면 벡터가 솔루션 LLM을 벗어나지 않습니다.
로컬 벡터 데이터베이스:
- LanceDB (내장, 기본값)
- Chroma
- Milvus
클라우드 벡터 데이터베이스:
- Pinecone
- Zilliz
- AstraDB
- QDrant
- Weaviate
🔐 보안 및 액세스 제어
Local RAG에서는 단일 사용자 모드와 다중 사용자 모드라는 두 가지 유형의 사용 사례를 지원합니다.
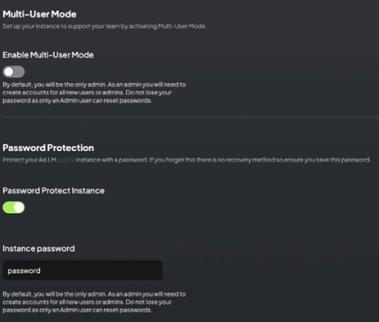
단일 사용자 모드
단일 사용자 모드는 자신 또는 신뢰할 수 있는 일부 그룹만 인스턴스를 사용하는 사용자에게 적합합니다.
- 완전한 제어: 인스턴스를 완전히 제어 가능
- 암호 보호: "Password Protect Instance" 옵션으로 인스턴스를 암호로 보호 가능
- 공유 접근: 암호를 아는 모든 사람이 인스턴스 사용, 모든 구성 변경, 모든 채팅 조회 가능
다중 사용자 모드 (권장)
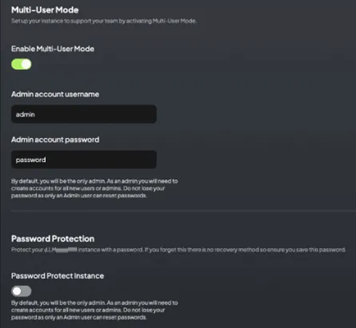
선호되는 사용 방법은 다중 사용자 모드입니다. 이 모드에서는 사용자별 역할 기반 액세스 권한을 설정할 수 있습니다.
사용자 역할:
Admin (관리자)
- 전체 시스템에 대한 전체 액세스 권한
- 모든 설정 및 로그 관리
- 사용자 계정 관리
Manager (매니저)
- LLM, Embedder 및 Vector 데이터베이스 설정을 제외한 모든 작업 공간을 보고 모든 속성을 관리 가능
- 제한적 관리 권한
Default (기본 사용자)
- 명시적으로 추가된 작업 공간에만 채팅을 보낼 수 있음
- 작업 공간이나 시스템 설정을 보거나 편집할 수 없음
다중 사용자 모드 활성화 후에는 단일 사용자 모드로 되돌릴 수 없습니다.
🛡️ 프라이버시 및 데이터 처리
데이터 보안
- 완전한 로컬 처리: 모든 데이터가 기업 내부에서만 처리
- 외부 전송 없음: 클라우드로 데이터 전송하지 않음
- 격리된 환경: 인터넷 연결 없이도 작동 가능
원격 측정
- 익명 데이터: 개인 정보 미수집
- 제품 개선: 서비스 향상을 위한 익명 사용 통계
- 비활성화 가능: 사용자가 원격 측정 비활성화 가능
당사는 제품 개선을 위해 원격 측정 데이터를 수집합니다. 어떤 이유로든 원격 측정 데이터를 저희와 공유하는 것을 원하지 않으시면 이 메뉴에서 해당 기능을 비활성화하실 수 있습니다.
💰 요금 정보
Local RAG 솔루션의 자세한 요금 정보는 요금제 페이지를 참고해 주세요.
📞 도입 문의
Local RAG 솔루션은 기업별 맞춤 구성과 설치가 필요한 엔터프라이즈 서비스입니다.
문의 방법
- 이메일: [email protected]
- 디스코드: kvidAI 커뮤니티
상담 시 제공 정보
더 정확한 상담을 위해 다음 정보를 함께 제공해 주세요:
- 사용자 규모: 예상 동시 사용자 수
- 문서 규모: 관리할 문서량 및 종류
- 보안 요구사항: 특별한 보안 정책이나 규정
- 인프라 환경: 서버 사양 및 네트워크 환경
- 통합 요구사항: 기존 시스템과의 연동 필요성
- 예산 및 일정: 도입 예산 및 구축 일정
🔗 관련 서비스
kvidAI의 다른 AI 서비스들:
문의 대응: 평일 09:00-18:00
답변 시간: 영업일 기준 1-2일 이내
기술 지원: 도입 후 지속적인 기술 지원 제공